Project 01
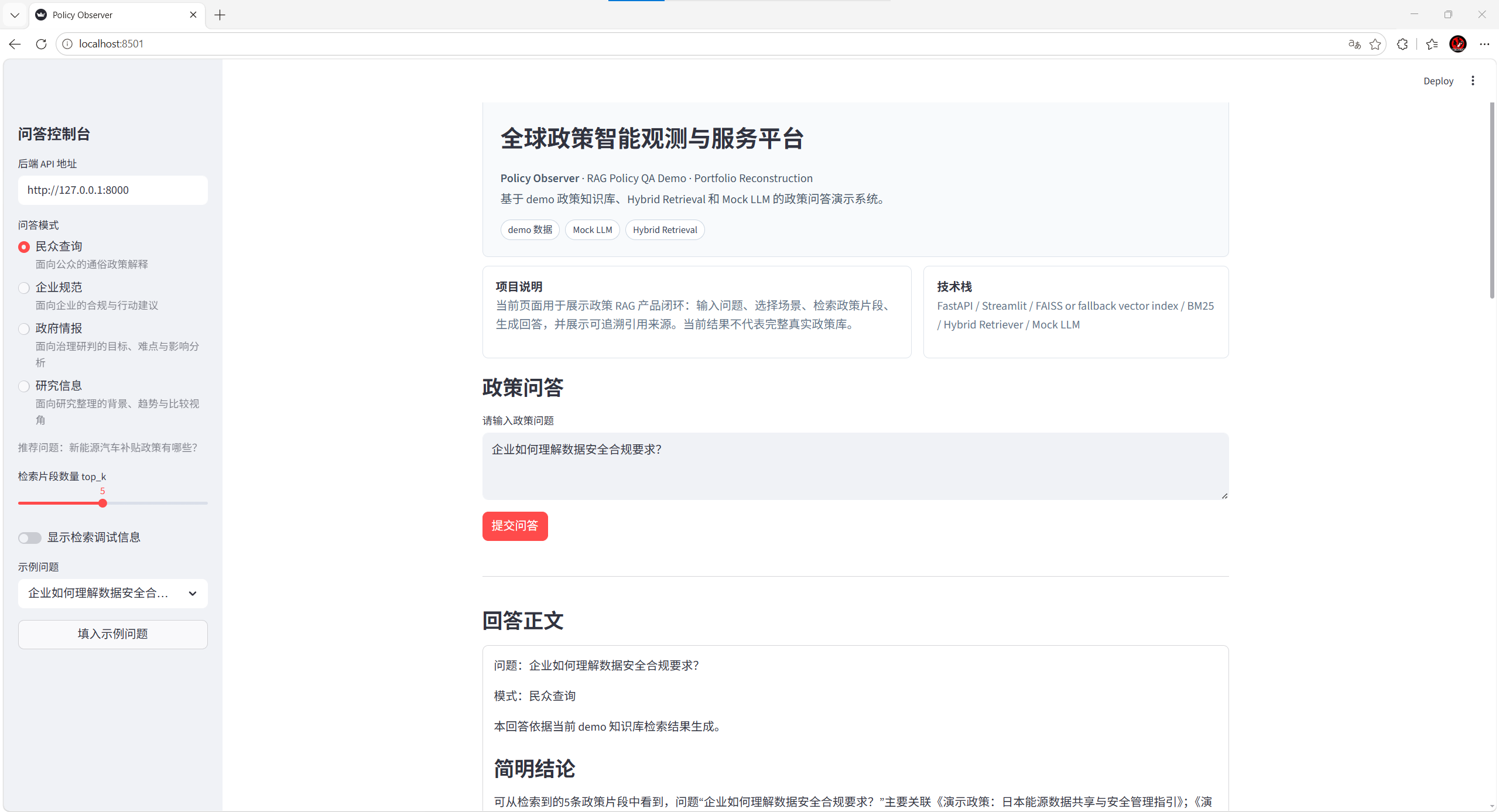
全球政策智能观测与服务平台
“全球政策智能观测与服务平台”是一个面向政策信息整合、智能检索与场景化问答的项目。项目结项材料中明确提出,平台以全球政策信息为对象,结合检索增强生成技术,覆盖政府情报、民众查询、企业规范和研究信息四类场景;在工程实现上采用分层架构、混合检索、结构化输出、接口服务与前端展示,使政策查询从传统关键词搜索升级为可追踪、可解释、可复用的智能服务。
项目定位与应用场景
项目针对政策信息跨地区、跨语言、跨部门分散的问题,建立以政策知识库为核心的智能服务平台。用户不需要在大量政策原文中逐条筛选,而是可以通过自然语言问题获取结构化解读、适用建议和来源依据。
平台服务对象被明确拆分为四类:政府情报场景强调政策要点、执行难点和风险提示;民众查询场景强调口语化解释、受益人群和办理建议;企业规范场景强调合规义务、风险识别和行动建议;研究信息场景强调主题归纳、证据追踪和研究线索整理。
- 政府情报:支持政策监测、趋势梳理和执行风险提示。
- 民众查询:将政策条款转化为可理解的申请条件、对象范围和办理建议。
- 企业规范:围绕合规要求、政策约束和经营风险形成行动化回答。
- 研究信息:为政策研究提供可引用、可追溯的证据片段和主题线索。
系统架构与接口能力
项目采用清晰的分层架构:数据层负责政策数据采集、清洗、字段抽取和知识库维护;检索层负责向量检索与关键词检索的组合召回;生成层负责基于检索证据构造提示词并生成结构化回答;服务层通过接口与前端承接用户查询。
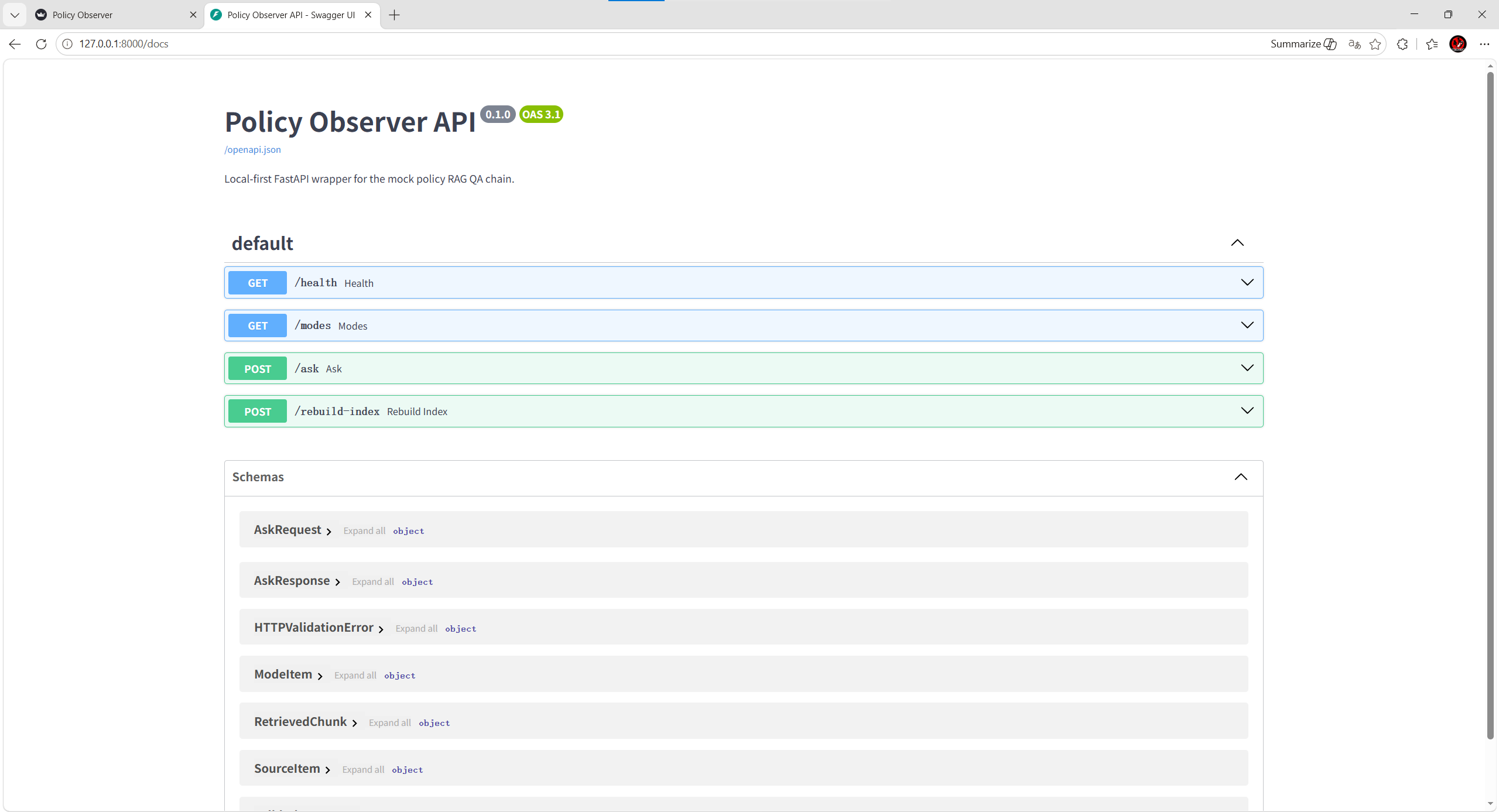
参考截图中的 FastAPI 文档展示了接口化能力,说明项目不只停留在脚本层,而是已经具备服务化雏形。API 层可以将检索、问答、知识库状态等能力提供给前端或其它系统调用,使政策问答平台具备进一步扩展为正式产品的基础。
- 使用 FastAPI 暴露可调试接口,便于检索、问答和知识库功能独立验证。
- 使用 Streamlit 承载前端交互,让不同用户模式、问题输入和结果展示可以直接演示。
- 使用本地知识库与轻量服务框架降低部署门槛,同时保留向量检索、大模型接入和分布式扩展方向。
知识库与混合检索
结项报告强调,项目将 RAG 技术用于政策信息服务,并通过向量检索与关键词检索的结合提升召回率和精准度。向量检索负责理解语义相近的政策片段,关键词检索负责保证术语、机构名、政策类型等硬匹配信息不被遗漏。
在系统实现上,HybridRetriever 承担组合逻辑:先对政策标题、正文和字段信息进行切分与向量化,再根据查询内容融合不同检索结果。配合分片索引、动态更新和检索质量控制,平台能够在政策数据不断增长时保持可检索性和响应效率。
- 政策数据字段包括标题、正文、发布时间、发布机构、政策类型和原文链接。
- 检索策略将语义召回和关键词召回结合,降低单一检索方法带来的漏召回和误召回。
- 知识库动态更新让平台能够持续吸收新政策,服务政策变化频繁的应用场景。
问答设计与成熟度
智能问答部分不是简单生成一段回答,而是围绕模式配置、提示词工程、多语言支持和结构化输出进行设计。不同模式拥有不同的回答重点,系统能够根据场景切换输出语气、信息颗粒度和行动建议。
项目成熟度体现在三点:一是有完整研究报告支撑,从问题背景到关键技术均有论证;二是有可运行工程结构,包括前端展示、接口文档和本地项目结构;三是有明确服务对象与应用案例,使项目从技术演示进入到政策信息服务产品的形态。
- 结构化输出让回答包含政策依据、适用对象、风险提示和行动建议等可阅读模块。
- 多模式问答让同一知识库能面向公众、政府、企业和研究者提供差异化服务。
- LRU 缓存、超时控制和分层架构思路体现了对高并发稳定性的工程考虑。