Project 03
当当畅销榜图书市场分析
当当畅销榜图书市场分析来自《数据分析与可视化》课程实验与论文,主题为“基于当当网畅销榜的图书市场结构与消费行为分析”。项目以 2021 至 2025 年畅销榜为数据来源,整理 2500 条样本,通过清洗、变量构造、可视化与出版理论解释,分析品类、价格带、热度、生命周期和用户偏好。
数据采集与字段体系
项目使用 requests 模拟浏览器请求当当网图书畅销榜页面,并使用 BeautifulSoup 解析 HTML。按年份和页码循环采集 2021 至 2025 年榜单数据,并通过请求头、编码适配、延时策略和异常处理提升采集稳定性。
采集字段包括年份、排名、书名、作者及发行公司、出版日期、出版社、原价、现价、折扣率和评论数。原始记录先被保存为 CSV,再进入 Pandas 清洗与特征构造流程。
- 时间维度:覆盖 2021 至 2025 年畅销榜数据。
- 榜单范围:总计 2500 条畅销书样本。
- 采集策略:按年份、页码和 CSS 选择器提取结构化字段,并通过异常捕获保证爬虫稳健运行。
清洗与变量构造
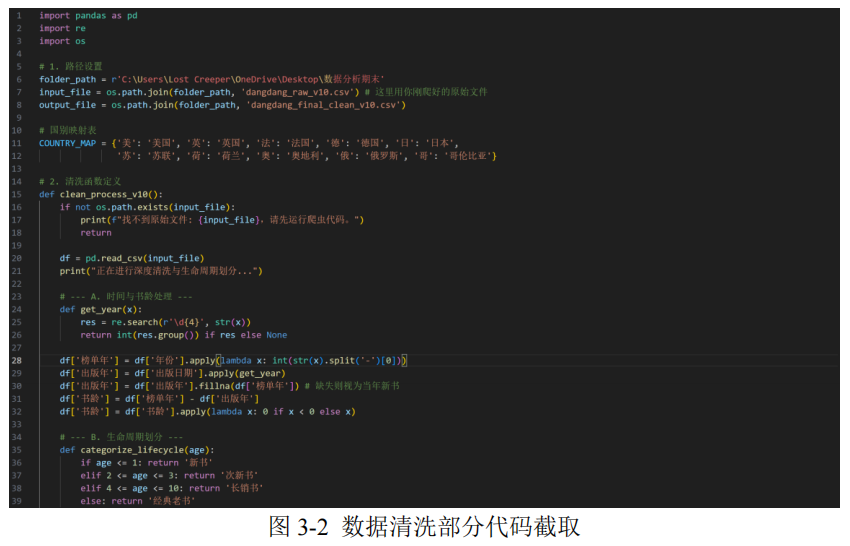
数据预处理是项目中最关键的工程步骤。报告中对书名营销性文字、出版年份、价格字符、折扣字段、作者国别和图书类型进行了系统清洗,使用正则表达式去除括号及其内部干扰内容,并将价格、评论数、折扣等字段转为数值变量。
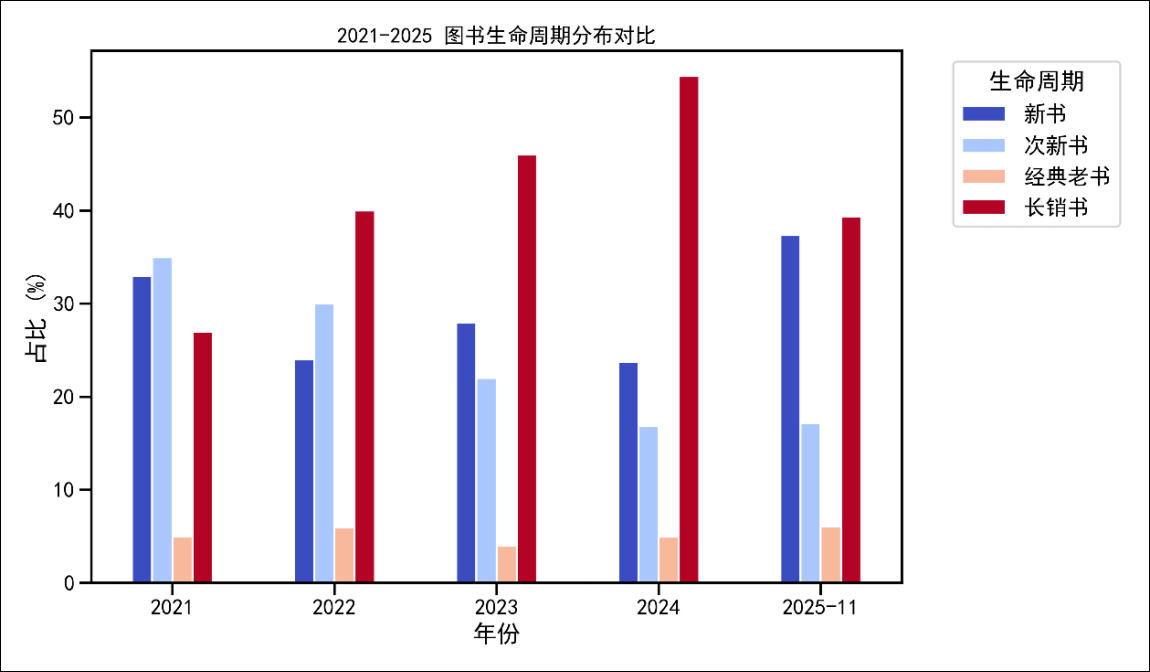
项目进一步构造书龄、生命周期、国别、类型和价格区间等解释性变量。其中生命周期被划分为新书、次新书、长销书和经典老书;价格区间被划分为 30 元以下、30-50 元、50-80 元和 80 元以上,用于解释不同类别图书的消费差异。
- 用 COUNTRY_MAP 统一作者国别标签,减少“美 / 美国 / [美]”等碎片化写法的影响。
- 用出版社与书名关键词共同判断图书类型,优先识别少儿教育、文学、社科等特征明显类别。
- 按同名图书聚合众数属性,修正多年份记录中的类型和国别不一致问题。
可视化分析过程
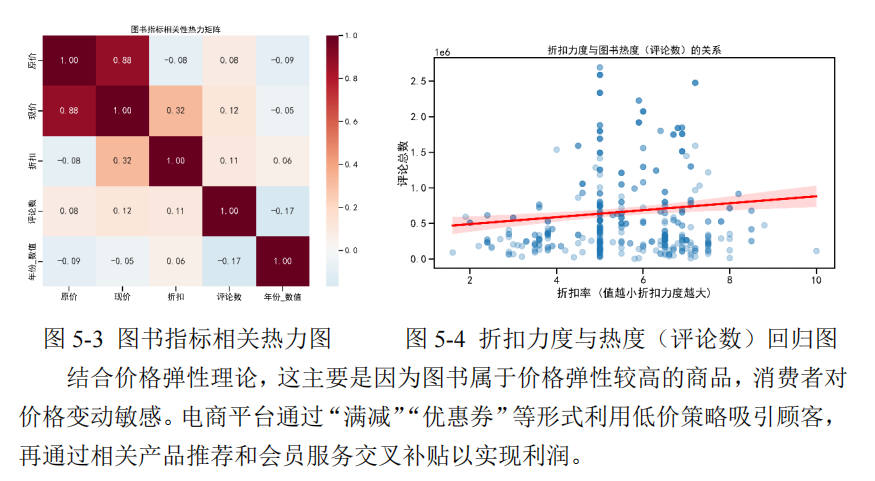
项目使用 Pandas、Seaborn 和 Matplotlib 进行图表表达,并强调“图是为了回答问题”。不同图表承担不同分析任务:交叉表与堆叠柱状图解释结构比例,面积图观察趋势变化,箱线图比较价格分布,相关性热力图观察变量关系,对数坐标用于处理评论数等高度偏态数据。
分析主题围绕四组问题展开:畅销榜是否被长期畅销书主导;不同图书类型在定价上是否存在差异;折扣是否影响文学、社科等感性消费类图书;线上平台环境下消费者需求是否出现分化。
- 生命周期分析用于识别经典老书和长销书在榜单中的稳定占比。
- 类型与价格分析用于比较儿童教育、文学社科、套装书和普通畅销书的市场定位。
- 折扣与销量波动分析用于解释 5-7 折区间的心理定价门槛。
研究结论与展示成熟度
论文结论显示,图书市场存在明显“马太效应”,销量和关注度仍主要集中在少数长期畅销的老书上。儿童教育类图书受家庭教育需求推动,价格敏感度相对较低,呈现高单价、套装化和教育投资属性。
文学与社科类图书更多体现感性消费,销量对 5-7 折区间较敏感。项目将这一结果放在平台经济与出版营销理论中解释,使数据分析不仅停留在图表层面,而是连接到选题策划、定价策略和差异化发行等出版实践问题。
- 数据链路完整:网页抓取、原始 CSV、清洗数据、特征变量、图表和论文结论一一对应。
- 研究框架完整:结合生命周期理论、长尾理论、STP/4P 和平台经济消费者行为进行解释。
- 输出形态完整:既有实验报告说明代码过程,也有课程论文承载研究问题和结果阐释。